Diagramme und speziell Graphen bilden die Grundlage vieler moderner Daten- und Analysefunktionen, um Beziehungen zwischen Menschen, Orten, Dingen, Ereignissen und Standorten in verschiedenen Datenbeständen zu finden. Data&Analytics-Führungskräfte verlassen sich auf Graphen, um schnell komplexe Geschäftsfragen zu beantworten, die ein kontextbezogenes Bewusstsein und ein Verständnis für die Art der Verbindungen und Stärken über mehrere Einheiten hinweg erfordern.
Gartner prognostiziert, dass bis 2025 Graphentechnologien bei 80% der Daten- und Analyseinnovationen zum Einsatz kommen werden (gegenüber 10% im Jahr 2021), um eine schnelle Entscheidungsfindung im gesamten Unternehmen zu ermöglichen.
Schnell wird deutlich: In der Logistik, wo genau die soeben genannten schnellen Entscheidungen in Verbindung mit komplexen Geschäftsfragen zum Alltag gehören, kann der Einsatz von Graphendatenbanken zum Wettbewerbsvorteil werden. Doch dazu müssen wir zunächst einmal klären, was genau Graphdatenbanken sind.
Was ist eine Graphdatenbank?
In der heutigen extrem vernetzten, digitalisierten Welt werden immer mehr Daten hinterlassen. Neben der reinen Zahl steigt auch das Ausmaß der Verknüpfungen zwischen den Daten selbst sowie die Anzahl verschiedener Datentypen. Herkömmliche Datenbanken sind in der Regel relational, das heißt, sie speichern die Daten getrennt nach Datentypen in Tabellen. Für miteinander verknüpfte Daten sind sie nicht ausgelegt. Graphdatenbanken können Datenzusammenhänge auf der Grundlage von Graphen hingegen sichtbar machen, diese zueinander in Beziehung setzen und bewerten.
Verwendet werden Graphdatenbanken beispielsweise zur Auswertung der Nutzerbeziehungen in sozialen Netzwerken wie Facebook oder des Kaufverhaltens von Nutzern im E-Commerce. Sie können aber auch im Supply Chain Management hilfreich sein.
Vorteile von Graphdatenbanken für die Supply Chain
Lieferketten sind häufig komplexe Gebilde, die verschiedene Ebenen umfassen. Sie erstrecken sich vom Hersteller über verarbeitende Unternehmen bis hin zum Händler, der das fertige Produkt an den Endkunden verkauft. Beispiel Automobilindustrie: Die Hersteller nutzen in diesem Bereich ein vielschichtiges und weitverzweigtes Netzwerk aus Lieferanten, Händlern und Partnern, die global kooperieren. Dabei verläuft die Supply Chain nicht geradlinig, sondern setzt sich über mehrere Ebenen hinweg fort. Hier eine 360-Grad-Transparenz zu gewährleisten, ist eine enorme Herausforderung.
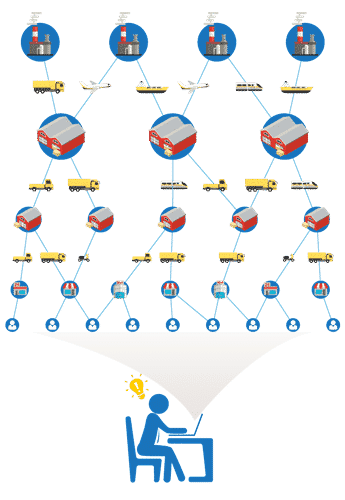
Doch gerade im Krisenfall gewährt eine durchgängige Nachverfolgbarkeit viele Vorteile. Muss ein Hersteller beispielsweise eine Rückrufaktion starten und dazu alle Produkte identifizieren, in denen das vom Rückruf betroffene Teil enthalten ist, sind Graphdatenbanken eine große Hilfe. Sie können stark vernetzte oder auch unstrukturierte Informationen anschaulich darstellen und ermöglichen nicht nur mehrere lineare Verknüpfungen, sondern auch Verknüpfungen in alle Richtungen zwischen den verschiedenen Akteuren einer Supply Chain.
Graphdatenbanken können also Zusammenhänge einer Lieferkette aufzeigen und alle direkten und indirekten Nachbarn eines Produkts, Bauteils oder Lieferanten identifizieren. So lassen sich große Datenmengen nicht nur strukturiert durchsuchen und verwalten, sondern auch problemlos ändern und neue Daten unterschiedlicher Art hinzufügen, etwa gesetzliche Neuregelungen oder neue Zulieferer und Produkte.
Ein weiterer Vorteil von Graphdatenbanken ist deren Performance. Die Abfragegeschwindigkeit kann im Vergleich zu relationalen Datenbanken je nach Anwendungsfall 100 bis 1.000 Mal schneller sein.
Graphdatenbanken verbessern die Transparenz der Lieferkette
Unternehmen verfügen über Gigabytes oder sogar Terabytes an relevanten Daten für die Lieferkette, die jedoch weit und breit in der Organisation verstreut. Graphdatenbanken sind ideal, um diese Daten als integriertes Ganzes zu organisieren und zu visualisieren, da sie das Netzwerk direkt abbilden. Darüber hinaus gibt ermöglicht die Graphanalyse tiefgreifende und komplexe Fragen zu stellen, die nicht nur die einzelnen Datenpunkte, sondern auch die Beziehungen zwischen allen zusammenwirkenden Gliedern der Kette umfassen.
Die Analyse von Lieferkettendaten erfordert die Zusammenführung verschiedener Datentypen aus internen und externen Quellen. Die Verknüpfung dieser Daten ermöglicht es dann den Managern der Lieferkette, die Vorteile der Grafik zu nutzen.
Nehmen wir das Beispiel einer Fabrik A, die ein Material X aus dem Lager B erhält.
Man kann dies als einfachen Fall oder als detaillierteren Fall darstellen, je nach Anforderungen innerhalb des Unternehmens und dem Umfang der Ressourcen, die man für den Aufbau einer Datenbank hat.
Einfacher Fall: Lager B -(liefert X an)- Fabrik A.
Dieser Detaillierungsgrad mag für manche Zwecke ausreichen, aber er lässt einige Lücken im Prozess, z.B. in der Transportlogistik, den Lagerbeständen, der Auftragsverwaltung und der Vertragserfüllung, was wohl den Zweck des Lieferkettenmanagements verfehlt. Würde das Unternehmen mehr Informationen vernetzen, hätte es einen besseren Einblick in seine Lieferkette und könnte so optimalere Lösungen finden.
Komplexer Fall: Fabrik A -sendet- Bestellung -an- Liefermanagementsystem -prüft- Hauptlagerliste (welches von mehreren Lagern oder Lieferanten könnte X zu den geringsten Kosten liefern, unter Berücksichtigung von Lagerbeständen, Transportkosten und vertraglichen Verpflichtungen?) -Zuweisung- Bestellung -an- Lager B (oder Lieferant B, wenn es sich um eine externe Organisation handelt) das wiederum -übergibt- Material X -an- Kurier -liefert an- Werk A.
Bei diesem Arbeitsablauf werden zusätzliche Schritte wie die Planung des Transports, die Erstellung von Frachtbriefen, die Zusammenführung von Aufträgen und die Entgegennahme der Sendung durch Werk A, das das Material zwischenlagert, oder die Weitergabe an die Produktionslinie einberechnet. Ja, sogar interne Prozesse können in diesem System abgebildet werden.
Je granularer man wird, desto mehr Daten werden erfasst und desto mehr Schritte in der Lieferkette werden der Analyse unterzogen. Und nachdem man diese Daten gesammelt hat, können Graph-Algorithmen eingesetzt werden, um sie zu analysieren.
Fazit
Der Einsatz von Graphdatenbanken im Lieferkettenmanagement ist sicher etwas für bereits fortgeschrittene Unternehmen und steht nicht am Anfang der Digitalisierung der Logistik. Doch schon heute nutzen innovative Unternehmen im Bereich der Lieferketten diese fortschrittliche Analysemethode, um bestehende Supply-Chain-Management-Systeme zu erweitern, Terabytes an Daten schnell zu erfassen und einen beispiellosen Einblick in ihren gesamten Betrieb zu bekommen. Auf diese Weise verschaffen sie sich mithilfe von Graphdatenbanken enorme Vorteile gegenüber ihren Wettbewerbern.